
综合新闻


现在的位置:主页 > 综合新闻 >
给点提示,就可以自动续写故事!NLP最强文本生(2)
【作者】网站采编
【关键词】
【摘要】可以看出,模型越大,它在可训练总数、层级数、学习比率方面的表现越高。 另外,从语料库来讲,模型越大越需要大的语料库作为支撑,GPT-3采用的数据
可以看出,模型越大,它在可训练总数、层级数、学习比率方面的表现越高。

另外,从语料库来讲,模型越大越需要大的语料库作为支撑,GPT-3采用的数据集(Common Crawl)包含了近一万亿个单词。
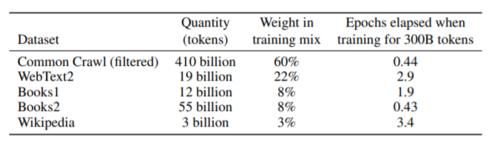
CommonCrawl数据是从2016年到2019年,每个月的CommonCrawl的41个分片中下载的,构成了过滤前的45TB压缩明文和过滤后的570GB,大致相当于4000亿字节。
请注意,在训练过程中,并非按大小对数据集进行采样,而是较高质量的数据集采样频率更高,因此,在训练过程中CommonCrawl和Books2数据集采样的次数少于一次,而其他数据集则采样了2 -3次。这本质上是接受了少量的过度拟合,换取了更高质量的训练数据。
因此,基于超大模型和与数据库的GPT-3在预训练阶段能够表现出极好的性能。
存在一定的局限性
不过,从此前的测试中,我们也可以看出GPT-3的文本生成还是存在一些局限性的。具体我们可以从Q&A;问答中来看一下。对于常识性性问题,GPT-3还是非常擅长的。如,

GPT-3自身的学习经验主要是从网上抓取,因此在回答一些常识性问题时,它可以从网上找到准确的对应答案。但在处理对于一些“不言而喻”的问题时,它就可以出现错误,比如下文:
Q:烤面包机和铅笔哪一个较重?
A:铅笔比烤面包机重。

虽然在这些问题上存在缺陷,不过,GPT-2在处理一些逻辑性问题,或者阅历理解任务时,几乎可以达到人类的水平。因此,在很多方面可以作为人类很好的辅助工具。?
文章来源:《商业故事》 网址: http://www.sygszzs.cn/zonghexinwen/2020/0722/394.html